[Unstructured to Structured ]Learn Relearn and Unlearn Technology
# Terms Used by Data engineer
>Tables: Only Structured
> Volume : All Types [Structured + Unstructured]
> Catalog Binding : Restricts User Permission
diffferent categories: 1. production 2. development 3. testing
> Scheme Provisioning :
- Dont need to explicitly define link/sync azure active directory
- when resource is leaving we dont need to explicitly remove id IF resource is leaving company is called scheme provsioning
- Storage Credentials
- External locations
- Celebal Tech Utility (UNITY LAUNCHER) => UCX Similar to unity launcher (UR Utility)
- Two level --> Three level namespace (UC only supports Three Level Namespace)
- If we use mount : we need to replace with external location
- If we use RDD replace with dataframe
- Group: Handles by user
- Service Principle: Handled by Machine
2 September Monday to 7 september Saturday
Index:
1.UC Technical Training
- UC Essentials
- Demo Training-1
- Demo Training-2
- Demo Training-3
- Demo Training-4
- Demo Training-5
- Day1: topics => Pyhton Basics
- Day2: topics=> Python Basics
- Day3: Topics => python Important Data Structuresa: list,tuple,dict
- Day4: Topics=> OOPS Concept
- OOPS Pillar :
- Class
- Object
- Data Abstraction
- Encapsulation
- Inheritance
- Polymorphism
Summary:
1. Unity Catalog Essentials:
- Overview of UC : 6 Sessions
- Compute Resource and UC
- Data Access Control in UC
- UC patterns and Best practice
- UC is central hub for administering and securing your data
- UC Enabels=> a. Access Control b. Auditing accross databricks platform
- Describe UC Key concept and how it integrates with databricks platform
- Manage groups, users and service principles
- create and manage UC metastore
Let's Understand Databricks Lake House Platform=>
1] Overview
Question: What it is?
Ans: It's Data platform that combines the DataLake + Datawarehouse and allows the organization to store, process and analyze data in various formats.
Question Whats it does ?
Ans: It provides Scalable Environment for DE + DS + ML and allows seamless data collaboration + Integration tools + Faster Insights.
Question : What Services Make it up?
Ans: Platform Integrates various service, Including:
- Delta Lake [For Structured + Unstructured Data management]
- Databricks SQL [For Querying and Visualizing Data]
- Databricks ML and Databricks Data-Science Engineering [For building and Deploying Machine Learning models...]
2] Key Components
Delta Lake:
- Storage layer => [ACID Transactions]
- Batch + Streaming
- Service for running SQL Queries on your data lake
- Scalable and Fault tolerant Stream Processing Engine built on Spark SQL Engine
- Set of core components that ensures high performance for processing large scale data,optimized versions of Apache Spark
- Combines [Data Lake + Datawarehouse]
- in single platform, eliminating need of seperate systems
- Understand how databricks handle data governance, security and data quality is crucial.
4] Common usecase
DE=> Building and managing data-pipeline to transform raw data into actionable Insights
DS=> Developing, training and deploying ML Models
Data Analysts=> Using SQL and other Analytical Tools to Explore and visualize data
5] Integration with other tools
Cloud Integration=>
- Integrates Major Cloud Platform like AWS, GCP, Azure
- Integration with tools like GIT,ML Flow, and other API's for better Collaboration and version control
- Data Governance in UC Video
- Key Concept in UC
- UC architecture
- Roles in UC
- UC identities
- Security Model in UC
- Data Access Control: 100 user in projects
- Data Access Audit: audit logs in DLT
- Data Discovery: Search bar
- Data Lineage: keeps track of data flow from source to destination
# Challenges in Data Lake are:
- No Fine-grained access(Control)
- No Common Metadate layer
- Non Standarad Cloud- Specific governance model
- Hard to AUDIT
- No Common governance model for data assests types (like: for hr data,employee data, client data , different sector data)
- Unify Governance Across Clouds
- Unify Data and AI Assests
- Unitfy Existing Catalogs
- Fined grained access for data lake across clouds based on open standard ANSI SQL
- Centrally Share, Audit, Secure and manage all data types with one simple Interface
- Work in concert with existing data,storage and catalogs : No Hard Migration Required
- Unity Catalog has Three Level Namespace
- Traditional two level : select * from schema.table
- Unity Catalog Three Level namespace: select * from catalog.schema.table
- view only
- can not modify data
- Cloud Storage
- Read-only logical collection
- Administers underlying cloud resources
- Storage Accounts/buckets
- IAM role/service principals/Managed Identities
3. Account Administrator
4. Metastore Admin
5. Data Owner
6. Workspace Administrator
- Principle -------Send Query ------->> Compute
- Access legacy metastore
- Managing Principle overview
- Adding and deleting user
- Adding and deleting service principals
- Adding and deleting groups
- Assigning Service principals, and groups to workspace
- Login Account console
- User Management
- Add User
- Main
- Permission
- Grain
- Name: db.analyst (Search Bar)
- User
- Test user
- Delete user
- User Management
- Service pricipal
- add service principal
- Name Terraform
- Identities
- nesting Groups
- User Management
- Groups
- Add Group
- Group Name: Analyst
- Account Console
- Workspace
- Student-MNF
- Permission
- Add Permission
- Search=> (User, group/ Service Principle)
- Account Admistrator Capabilities
- Cloud Resource to Support the Metasstore
- Completed the Managing Princicple in UC Demo
- Log in
- Data
- create metastore
- Name => main us-east
- Region=> N.virginia
- S3.bucket path
- IAM Role ARN
- Create
- Skip
- A Metastore must be located in the same region as a workspace being asign to...
- Administrators can be assigned to multiple workspace as long as all are in same region
- An Workspace can only have 1 Metastore at any given time
- Data
- Development
- Workspace (TAB)
- Assign to workspaces
- Data
- Development
- Owner=> sauru@databricks.com
- Choose another user
- Describe UC key Concept and how it integrates with databricks Platform
- Manage Groups, User And Service principals
- Create and Manage UC Metastore
- Importance of UC
- Features of UC
- Metastore
- Two-level Namespace vs 3 level namespace
- Storage Credentials and External Location
- Databricks Workspace: Before and After UC
- Improves Data Values
- Reduce Data Cost
- Increase Revenue
- Ensure Security
- Promote Clarity
- Simplifies Data System
- Discovery
- Access Control (Only Authorize users)
- Lineage
- Monitoring
- Auditing
- Data Sharing
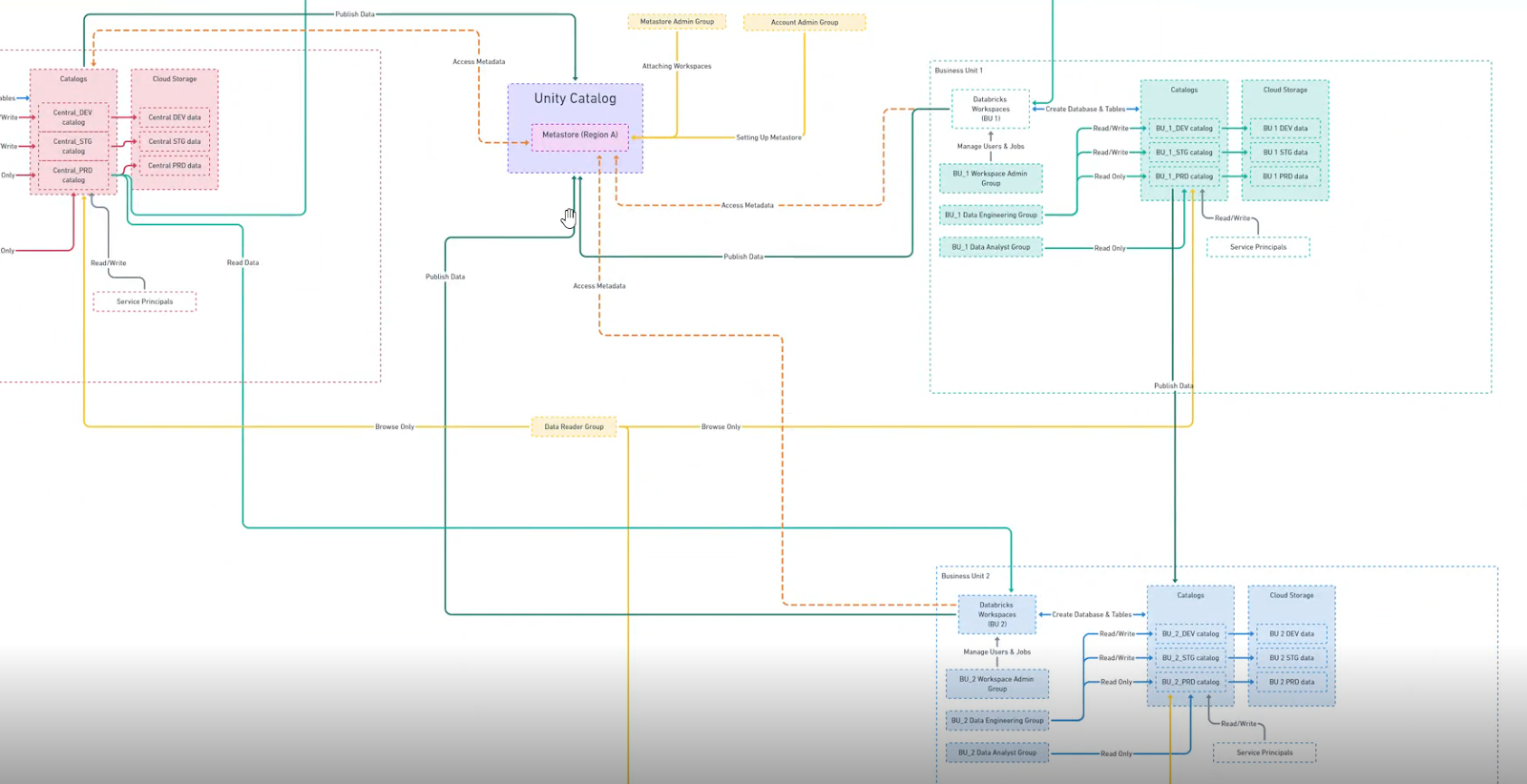
- Metastore : Top Level container | Data and Meta Data of all data in databricks workspace
- Audit Log : actions and event on data like DLT Framework in databricks
- Account Level Management
- Storage Credentials
- ACL Store
- Access Control : roles and policies
- Data Explorer : interface for browsing and discovering data assets
- Lineage Explorer : Data Flow (Source to Destination)
- Top Level Container
- Data and Meta data of all data in databricks workspace is stored in one centralize repository i.e Metastore
- Note:
- In 1 Region=> only 1 metastore
- Under 1 metastore => Multiple Databricks Workspaces
- Metastore> catalogs> schema> view,table,volumes,model,functions
- select * from schema.tablename
- With use of unity catalog it provides feature to create multiple catalog apart from the HIVE Metastore (Eg: Catalog 1, Catalog 2, etc.... depending on business use case.)
- select * from catalog.schema.table
- By Creating Different catalogs we can seggregate the organization data depending on different departments
- Eg:
- Finance Department
- Data Engineering
- Data Analyst
- Production, Development, Staging Data
- Once a storage credential is created access to it can be granted to principals (users and groups)
- Before and After UC
- Lineage
- What's Workspace Level Catalog binding
- Cluster Level Catalog binding
- Notebook Level Catalog Binding
- Dicussion of migration assests as part of this unity catalog migration like:
- Table Migration
- Cluster Migration
- Job Migration
- This Feature is availbale only in unity catalog not in hive
- Eg: lineage direction: upstream and downstream
- code : select * from <<upstream>> <<downstream>>
- The Catalog Binding is in three level
- Workspace
- Cluster
- Notebook
- Three Level Namespace we can use two Level also here... this is catalog binding
- Setting> advance > other>default> catalog(set) for 2 level
- Before it was three level but now we enabled the option of 2 level both three level and 2 level gives same output
- hms_externl_cloud_table
- hms_external_dbfs_table
- hms_managed_table
- we create table
- Each Hivemetastore table will be migrate to UC
- Replicated data of metadata in Unity Catalog
- Compute
- All Purpose
- More.... Clone
- Change Name of Cluster to UC Cluster
- Policy: Unrestricted
- Mutlinode
- Access Mode: Single User/Shared (UC is enable for 10.4 version LTS & above only)
- Photon => ON/OFF
- I Am Role
- Enable Credential pass through
- (Dont enable it... UC will not be avilable)
- Deep Clone
- SYNC
- CTAS
- Lineage
- Binding
- Data Assets Migration Like:
- Table Migration
- Cluster Migration
- Jobs Migration
- Improves Security



- Question 1] Role Based Access Control : See on MS Account documentation
- Question 2] Service Principle Create and its Access
- How Does UC differfrom hive meta store?
- How would you map Hivemetastore permission to Unity Catalog ?
- After Hive to UC table (How to validate data and schema are correct ?) ans: Validations ---> Table Count: Rows, and Columns
- Question 3] How Does UC handle Mutli tendancy ?
- Question 4] How can you acces audit data access in UC?
- Question: manage table , external table at dbfs ||| I migrate hive to UC ans: create table as select [CTAS]
- Workflows list
- Start or stop workflow using API
- Cluster List (Show...)
- Workspace NB Counts ---(Start| STOP |Terminate Cluster)
- Create Cluster Through API
- Notebook list
- API through stop job [Pause it]
- RDD
- Dataframes
- You Can use anywhere
- It Depends on Data
- Data Shffling(More)
- By Default : 200 Partitions , 200 tasks
- If you say you want less partitions eg: 10 or 50 then its repartitions
- Har ek parttitions se 1 task Banta Hye
- It depends on kitne hamare narrow/ wide transformation hye
- Data Schema
- Partitions
- Optimization Techniques... etc
- Python Fundamentals
- Why Pyhton
- Pyhton vs Java
- Python variable
- Python Data types
- String Functions:
- upper
- lower
- capitalize
- lstrip
- rstrip
- startswith
- endswith
- Methods:
- split
- join
- python list and its functions
- python tuple and its functions
______________________________________________________________________
>>> Spotify End to End Pipeline Project PPT Preparation
Module 1:
- ETL Pipeline
- Architecture
- Spotify API
- Cloud Providers : AWS
- AWS Services
- Storage => Amazon S3
- Compute => AWS Lamba
- Logs/Triggers => Amazon Cloud Watch
- Data Crawler => Crawler
- Data Catalog => AWS Glue Data Catalog
- Analytics Query => Amazon Athena
- Go to Spotify: Sign up
- Jupyter Notebook (Python Libraries)
- Client ID, Secret ID
- Write Python Code: To Extract Data from that spotify API (Perform All Transformation on that data....)
Module 3:
- AWS Account needed
- Selection Region: North Virginia
- Billing Dashboard : (Receving Billing Alerts)
- Moving Data
>>> SCD and CDF Implement practically
From Rajas DE
>>> SCD Types
Slowly Changing Dimensions (SCD) can be implemented using Delta Lake, which provides capabilities for handling big data and supports ACID transactions,
# Types :
- SCD Type 1 (Overwrite)
- SCD Type 2 (History)
- SCD Type 3 (Add new attribute)
- SCD Type 4 (Historical Table)
- SCD Type 6 (Hybrid SCD)
_______________________________________________________________________
A Slowly changing Dimension (SCD) is a dimesion that stores and manages both current and historical data over time in a data warehouse (Source System). It is Considered and implemented as one of the most critical ETL Tasks in tracking the history of dimension records
# Types=>
- SCD Type 1 (Over writing on existing data)
- SCD Type 2 (Maintaining No. of times history as creating another dimension record )
- SCD Type 3 (Mainiaining one time history in new column)
- If you dont want to maintain any history in your target variables
- Eg: Customer Changes Address
- # if you dont want to maintain any history
- Maintianing History as More no. of records
- Eg: Customer Phone Number
- # If you need all history
- Maintain one time history in new column
- # If you dont need any history
Reference of video : Youtube Techlake Channel
~sauru_6527
30 th august 2024
________________________________________________________________________
>> Atharva Interview Questions
> Python
- Split Code
- Join Code
- Count of Vowels Code
- Exception Handling
- List, tuple
- Architecture
- Cache Persit
- Coalesce Repartition
- Catalyst Optimizer
- AQE
>> Change Data Capture(CDC) ~ Seattle Data Guy
A] Intro
CDC [Change Data Capture]
- Capture the Changes [Insert Update Delete] that Appears in database and these changes are stored often in sort of logs

> Real Time Data Landscape:
- Open Source :Eg: Apache Spark
- Hybrid :Eg: Databricks
- Managed Service : Eg: Delta Stream

B] Write Ahead Logs [WAL]
- Common Approach used is WAL

- Realtime Data (If you want to do realtime analytics...)
- Historical Data Preservation
D] Where i have used CDC ?
Example of CDC Solutions that i have used in PAST

>> Now I have to do the CDC by Rajas DE
27 th August Tuesday 2024
Tasks to told today
- CDC, CDF From Youtube intro
- Rajas DE Playlist
- UC Migration Links sent By Pratima Jain
- CDC,CDF,Apache Spark, Rajas DE Playlist, UC Migration Links + Be prepare for the Interview
- Do Leet code in parttime
- Do Apache Spark Course
- Do Rajas Data Engineering Playlist Make A plan to complete 133 videos
- Do 30 Pyspark Questions
- Taxi Sheet Questions to do
- UC Migration (Main Project Where mam is working)
- PyCharm: Daily Practice i.e(@ PG Complete the Darshil python Course Again)
- Make PPT Of Topics Covered till date today and submit to Mayank
________________________________________________________________
Today's Date: 23 August, Friday 2024
- Two Tasks given by Nishitha Mam are # Task 1 and Task 2 Refer: Intern Group on Teams [yet to do...]
- 30 + Pyspark Questions [5 Done...] [yet to do...] : pyspark.xlsx
____________________________________________________
>> Four Questions based on project
Q1) Estimate of 1000 GB data
- Driver: 4 Cores, 32 GB RAM Memory
- Executors : 3 Executor per Instance
- Instance : 2
- Cost : $ 2.17 Per Hour => 182.6 Per Hour
- Understand Medaloin Archi
- Generate Random function in python and then apply autoloader on it
- DLT (Delta live table)
- 5 Questions Done (2 Remained...)
- wigets concept in it...
>>> Questions By Pratima
>>> Cluster/ Compute
1] All-Purpose Compute
- Analyze data in NB
- Create, Terminate and Restart
- Cost: Expensive
- Just Support Running a NB as Job
- No restart
- Cost : Low
- Instance Pool, it is as pool of resources (Set Of VM) (Swimming Pool)
- Eg: If you have job that requires a lot of processing power you can assign more instance from pool
- If workload decrease's you can release the instance back
- Optional (On/Off)
- Improves Performance, use when multiple sql code, Optimal in cost
>>> Databricks Architecture
>> Control Plane:
- Cluster Manger
- Handled By Databricks
>> Data Plane:
- Storage: VM, BLOB
- Handled by Cloud Provider (Azure, GCP)
>>> Unity launcher (Celebal Product)
- Boost Your UC Migration By 70%
>>> Tree in UC
Levels :
- Metastore
- Catalogs
- Schemas
- Tables, Volumes
>>> Prerequisites in UC
- Latest: 11.3 LTS
- Current: 10.4
>>> 3 Workspace Environment in Project using UC
- Development
- Testing
- Production
REST API Understanding
1: Introduction To REST API
Rest API (Representational State Transfer)
AP => Application programming interface
If your application is DYNAMIC => Eg: ZOMATO
Dynamic App (Zomato) -----> (Request) -------> Websever
<----- (Response) <-------
we get response in HTML and JSON Format
but here we get response in unstructured day
HTML Response => WRONG
We need Structures => Right (Eg: 1 value)
> JSON format (dict,key)
>Xml format (hierarchical datastructure )
>>> Isssue: We need a lot of methods to get required information from server to solve this Issue we use REST API
> Rest API defn:
Rest API creates an object and there after sends the values of the object in response to client request
OBJECT => IMPORTANT POINT (Only 1 Object value we get )
> Eg:
city : Jaipur
restaurant name : Moms tiffin
food item : Dal bati
this above data is send to our DYNAMIC APP (ZOMATO)
2: REST API Connection With Databricks usings Fake API Json placeholder
code:
>>>>> YOUTUBE SECTION
Links to refer :
> YouTube Videos and playlist:
> Channel name : Rajas DE
> Unity catalog in 60 Seconds : Youtube
Youtube Video 1: Connect REST API in DataBricks via JSON placeholder [yet to do]
Summary: Youtube Video
Important :
Create API endpoint =>
Eg: url = "https://jsonplaceholder.typicode.com/post/1"
Youtube Video 2: How to get Access Token in DataBricks [steps..]
Summary:
Steps :
- user>user setting
- developer>access token
- manage>generate new token
- Copy and Use that token wherever you want
.
.
.
Questions By Pratima Mam
Note : Solve it using REST API, refer this docs : Link
Question 1: Fetch All the schemas present in hive metastore, so i want list
Question 2: Fetch all the tables present in each schema
Question 3: I want Count of tables and views of each schema
Sample OP =>
Schema Name: employee
View(Count) : 15 Views
Table(Count) : 10 Tables
Addn Question 4: Get the Number of Workflow and notebook in your Databricks Account
.
____________________________________________________________________________
>>> Doubted Questions: [Don't Be DoubtFul Ask Questions and get its answer bro]
- What is your name ?
>>>>> Full Roadmap of associate DE-DBC
- Lakehouse (24%)
- ETL With Spark SQL and Python (29%)
- Incremental Data processing (22%)
- Production Pipelines (16%)
- Data Governance (9%)
- Benefits of Unity catalog
- Unity catalog features
- Configuring access to production tables and databases
- Creating different levels of permissions for users and groups
- Data Governance
- Defn
- With and Without UC
- Key Features
- UC Catalog Object Model
- Metastore
- Object Hierarchy in metastore
- Working with database objects in UC
- other Securable Objects
- Granting and revoking access to database objects and other securable objects in uc
- admin roles
- managed vs external tables and volumes
- Data isolation using managed storage
- workspace catalog biniding
- auditing data access
- tracing data Lineage
- Lakehouse Federation and UC
- Delta Sharing, Databricks Market Place and UC
- How i setup Unity Catalog for my organization
- Migrating an existing workspace to UC
- UC catalog requirement and restrictions
- Region Support
- Compute Requirements
- File Format Support
- Securable Object naming requirements
- Limitations
- Resource Quota
- Data And AI Summit 2023 : Whats-new-unity-catalog-data-and-ai-summit-2023
2. Entity Permission
# Configuring Access to production table and databricks
- Manage privileges in UC
- Who can manage Privilege
- Workspace Catalog Privileges
- Inheritance Model
- Show Grant And Revoke privilege
- Show grants on Objects in UC metastore
- Show my grants on objects in UC metastore
- Revoke permission on object in UC metastore
- Show grants on metastore
- Grant Permission on metastore
- Revoke Permission on metastore
- Access control lists
- Access control list overview
- Manage Access control list with folders
- AI/BI dashboard ACLS
- Alerts ACLS
- Compute ACLS
- Legacy dashboard ACLS
- Delta live tables ACLS
- feature tables ACLS
- File ACLS
- Folder ACLS
- Genie Space ACLS
- Git Folder ACLS
- Job ACLS
- ML flow experiment ACLS
- ML Flow model ACLS
- Notebook ACLS
- Pool ACLS
- Query ACLS
- Secret ACLS
- Serving Endpoint ACLS
- SQL warehouse ACLS
- Data governance with UC
- Centralize access control using UC
- track Data lineage using UC
- Discover data using Catalog explorer
- Share Data using Dela sharing
- Configure Audit Logging
- Configure Identity
- legacy data governance solutions

Comments
Post a Comment