[ STRUCTURED Databricks ]
>>>>> Databricks Cluster UI (~ Ref Youtube Video : ~Mr.Ktalks Tech )
# Cluster Diagram

Explanation:
Cluster :
Nodes and Executors
- Set of VM
- 1 Node = 1 Executor
- Each Executor : has 1/more Cores
- 1 Core = 1 Partition
- Each Core : takes 1 task and used for parallism
Driver :
Step 1: Write Code in Driver
Step 2:
Everything get's Divides into STAGES and TASKS
This is Done with help of DAG
DAG: divides all jobs in form of stages and task
each TASK: executes on executor
each EXECUTOR: it made of essential cores
each CORE: define degree of parallelism
that will happen when JOB RUNS....
# Cluster:
- Set of Virtual Machines to do work
- Creating Computer Resources for processing BigData
- Types: 1] All Purpose Compute 2] Job Compute
1] All-Purpose Compute [Everything]
- Analyze data in NB
- Create, Terminate and Restart
- Cost: Expensive
2] JOB Compute [Just to run NB as Job with ADF pipeline and Databricks]
- Just Support Running a NB as Job
- No restart
- Cost : Low
3] Pools (Set of VM)
- Instance Pool, it is as pool of resources (Set Of VM) (Swimming Pool)
- Eg: If you have job that requires a lot of processing power you can assign more instance from pool
- If workload decrease's you can release the instance back
Pic:
>>>Photon
- Optional (On/Off)
- Improves Performance, use when multiple sql code, Optimal in cost
- Its Vectorized Engine in databricks : For high performance to SQL workloads
Pic
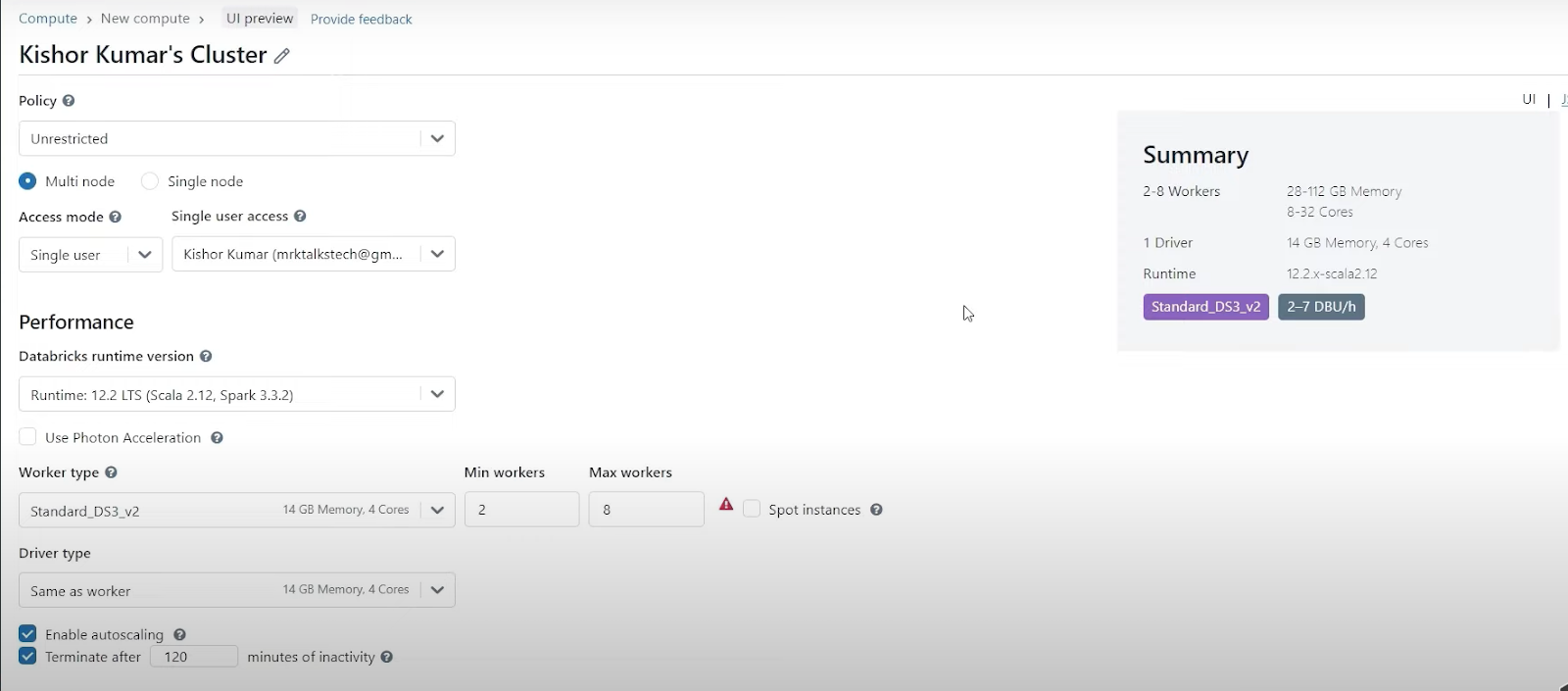

# Policy (Important)
- Unrestricted
- Personal Compute
- Power use Compute
- Legacy Shared Compute
1. Unrestricted:
- All options Available like Node type, Worker type, Min Workers, Max Workers
2. personal Compute
- Missing Options Like (Eg: We Dont have Options like worker type)
# Multi node [Multiple Options Available]
- High Cost and Massive Data
- Has Driver + Worker Node
- Used by group of people working on same single cluster
- Same cluster at same time running but still they will get optimal performance
# Single Node [~ Similar to Personal Compute]
- Less Cost Less Data
- Less features/options(You Can not select driver and Worker Node)
- Used by single user for myself eg: sql, python, scala queries

# Access Mode (Important)
- Single User =>All Language
- Shared => Python,Sql
- No isolation Shared => All Language
1.Single User
- Only person who create cluster can access it.
- All Programming languages support => Pyspark, SparkSql, SQL, Scala
2. Shared
- Cluster can shared to run Notebooks
- Downside (Only Python, SQL) Supported
- We Need Here Premium Version of Databricks
- User Need Access of file Datalake from databricks
3. No Isolation
- Similar to Shared (All Language Support)

# Performance
DB Runtime Version:
Options: 1. Standard 2.ML
1. Standard:
- 13.1
- 13.0
- 12.2 LTS Scala 2.12, Spark 3.32
- 12.0
- 11.3 LTS
- 10.4
Note: Latest Version of Spark 3.5.2 (Release on 10 August 2024)
2. ML:
- Note: Seperate Versions for ML Task

# Photon (On/Off)
- Improves Performance, Multiple SQL based Codes, Minimal Cost

# Worker Type (CPU and Memory: Actually Does Task)
- Standard DS3_V2 (14 GB Memory, 4 Cores)
- Min Workers: 2
- Max Workers: 8
Note: Higher Node, Higher Cost
Refer : azure.microsoft.com/en-us/pricing/details/databricks/

# Driver Type (Team Leader)
- Identifies Different Task need for operation,
- worker node actually performs the task
# Enable Auto-Scaling (ON/OFF)
# Terminate after => 15 Min of Inactivity
___________________________________________________________________________________
Thanks for Reading ~sauru_6527

Comments
Post a Comment